The Challenge
A top European electronics retailer listed more than 500,000 products from thousands of brands. Customers relied on filters to find the right item. But: The site’s attribute data was inconsistent. Variant names conflicted with images, colors were mislabeled, and some products carried the wrong brand.
Baymard’s research shows that weak product lists and filtering can push abandonment as high as 67 to 90 percent, while optimized implementations cut that to 17 to 33 percent.
The business impact extended beyond conversion. Returns surged when items were “not as described.” Processing returns typically consumes 20 to 65 percent of an item’s value. (Total retail returns in 2024 were projected at $890B!)
Our client attempted to manually correct the data with 15 full-time content specialists, but the effort concentrated on the top two percent of SKUs. The long tail remained messy, which limited category analysis and made assortment decisions slow and error-prone.
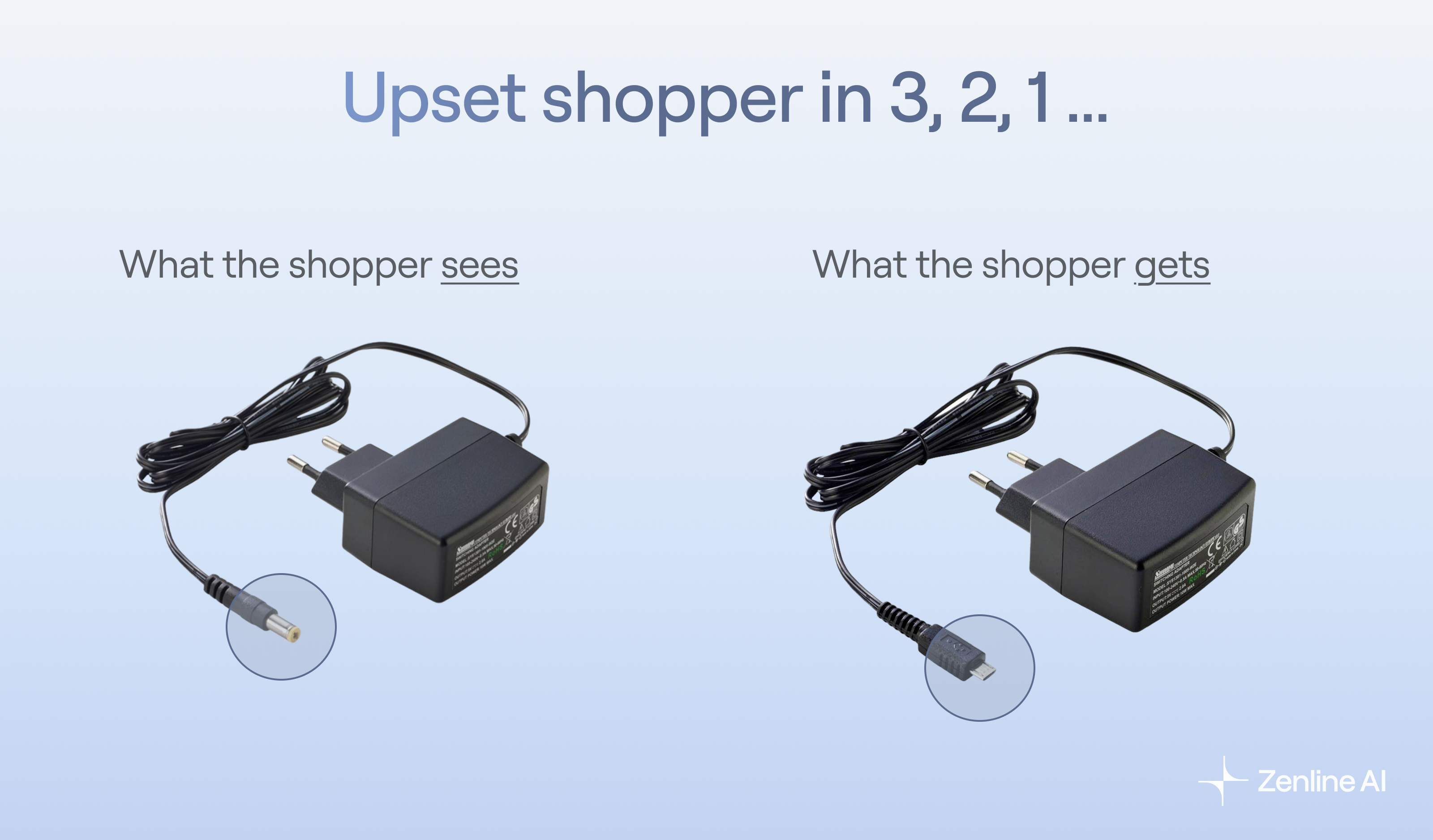
The Solution
The retailer deployed Zenline’s Data Steward (Cleaning Agent) across the online catalog. Integration started with public product data to avoid IT dependencies, then moved to read–write updates into STEP PIM once results were proven.
What the Agent did
- Attribute normalization and enrichment: Canonicalized color, size, capacity, compatibility, and pack size.
- Vision–language cross-checks: Compared titles and attributes with product images to detect color and variant mismatches.
- Brand and variant governance: Flagged incorrect brands, harmonized variant naming, and mapped products to a canonical taxonomy.
- Duplicate and near-duplicate resolution: Merged redundant SKUs and reconciled EAN conflicts.
- Human-in-the-loop QA: Low-confidence suggestions routed for review; one-click write-back into STEP PIM after approval.
What it found
- About 5% of products contained impactfully wrong data.
- 20–25% of products were missing attributes that matter for filters and purchase decisions.
- During the test phase, over 99% of suggested changes were approved without edits. The Agent now applies fixes automatically.
“We thought search was the issue. The Agent showed us the root cause was our own product data. It corrected colors, variants, and brands across hundreds of thousands of items. Our teams stopped firefighting and finally trusted the catalog.”
VP Product Management, Electronics Retailer
The Impact
Customer experience and revenue
- More complete and consistent attributes increased filter coverage on listing pages. Baymard’s benchmarks link better product lists and filtering with much lower abandonment, which aligned with the uplift observed on cleaned categories.
- Fewer “wrong color” and “not as described” returns. Avoided return costs matter because each return often consumes 20–65% of item value and the industry-wide burden is massive.
Operational efficiency
- The 15-person content team stopped backfilling roles as people left. AI now maintains quality across the entire long tail of 500,000+ products rather than only the top sellers.
- Category managers receive accurate counts by attribute and ingredient/spec, which speeds assortment reviews and reduces rework.
Governance at scale
- Continuous monitoring prevents taxonomy drift and brand mislabeling.
- Write-back into STEP PIM keeps downstream channels consistent.
Why it worked
The program attacked the silent blockers that suppress conversion and inflate returns: incomplete attributes and mismatched variants. It delivered coverage and consistency at machine speed and then institutionalized the fixes through PIM write-back and ongoing QA.
