Every product decision in retail is only as good as the data behind it. Whether you’re deciding what to delist or how to price, the question remains the same: do you have the right signals to act with confidence? At Zenline, we’ve built our entire product around that question. That’s why Zenline’s AI agents are designed to work with real-world data environments – messy & complex. And that’s okay. Zenline was built to work even when data is incomplete or missing. In fact, the AI can already generate first assortment insights based on external data sources alone, including competitor pricing and online demand signals. This enables fast category scans.
This article explains which data sources Zenline uses, why they matter for assortment decisions, and how the system handles imperfect or incomplete information.
External data
Strong assortment decisions are never made in isolation. That’s why Zenline adds a layer of intelligence by integrating publicly available external data. This gives category teams the context they need to stay competitive and market-relevant.
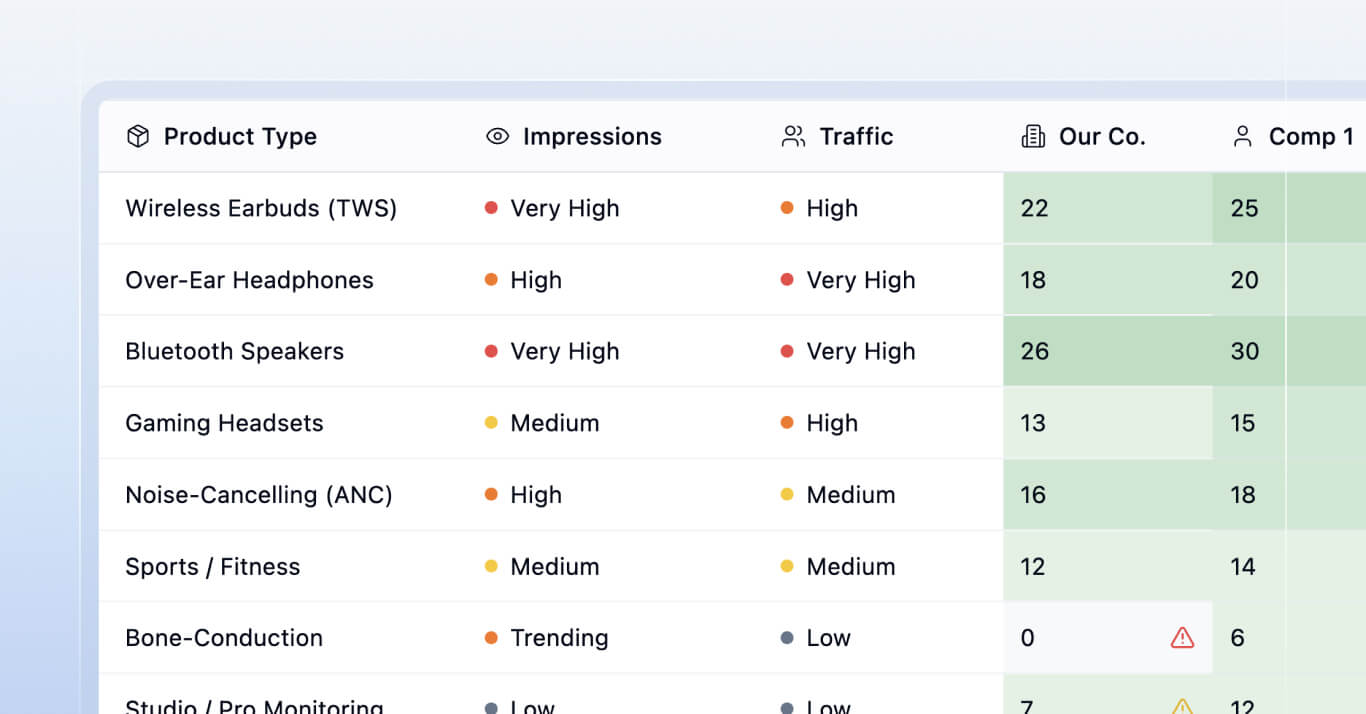
1. Competitor assortment and pricing
Zenline continuously tracks product listings and prices from key competitors. It maps competitor products to your assortment using similarity models, allowing it to benchmark your pricing logic, identify assortment gaps and flag risks like undercutting or overexposure. We also scrape comprehensive performance indicators from competitor websites including ratings, reviews, best seller tags, inventory availability, and product rankings to provide deeper competitive intelligence.
2. Search and social trends
Zenline monitors Google Search, YouTube and TikTok to detect emerging product interest and fast-growing topics. These signals are filtered, scored and linked to your categories. This helps validate launch decisions, surface category expansion opportunities, and avoid missing out on demand shifts that haven’t yet shown up in your own data.
Internal data
Zenline connects to four core internal data sources. These are the signals that come directly from your business and form the basis for most commercial decisions.
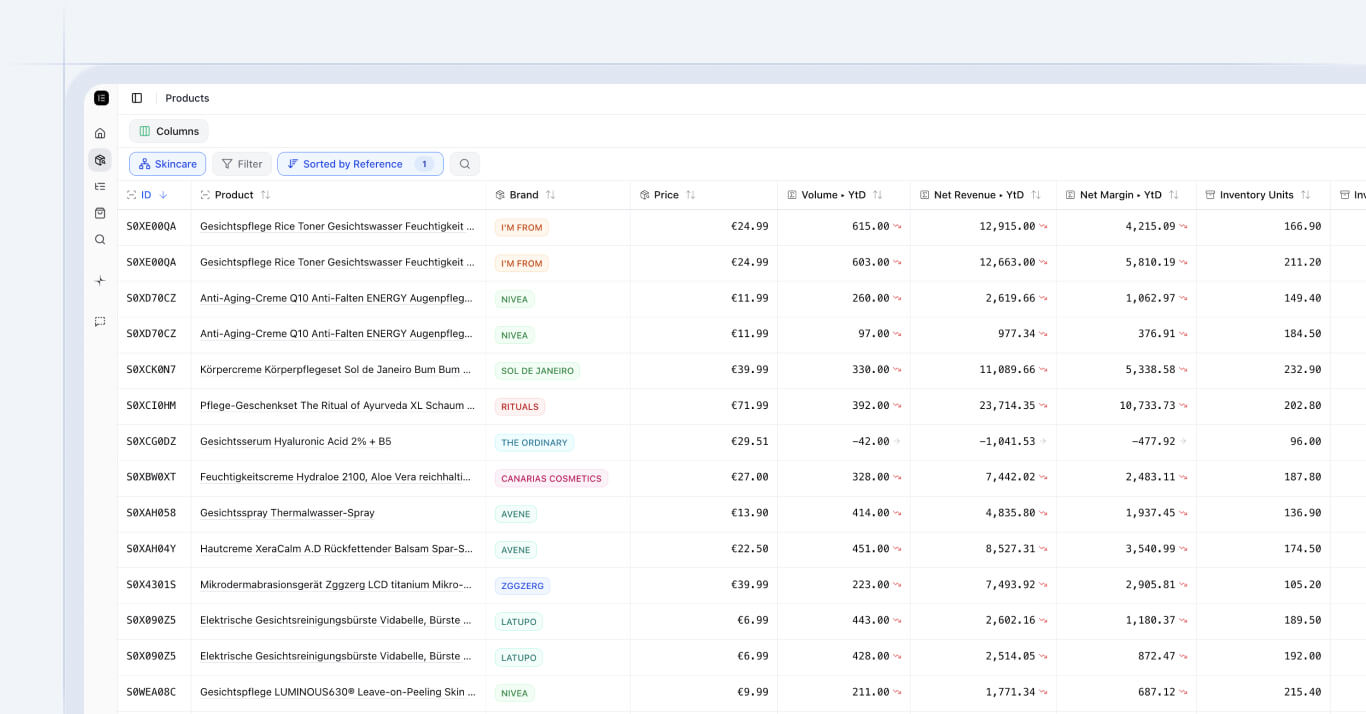
1. Sales data
Zenline analyzes historical transactions to understand product demand over time. It doesn’t just look at totals, it evaluates sell-through, sales volatility, basket behavior and seasonality. This helps detect underperformance, substitution effects and traffic-driving items. It also powers lift analysis, revealing which products are commonly purchased together.
2. Margin data
Zenline combines cost of goods sold (COGS), selling prices and promotional history to calculate contribution margins per product. These insights help flag products that may sell well but erode profitability, or identify margin-improving pricing opportunities within a category.
3. Master / PIM data
Product hierarchies, categories, attributes and brand information help Zenline cluster products and identify overlaps. Even if your master data is messy or inconsistent, Zenline’s multi-modal AI can infer structure using product names, images and attributes. This is crucial for detecting duplicate products, cannibalization or opportunities for consolidation.
4. Inventory data
Zenline integrates stock levels to contextualize sales. A product might appear to be underperforming, but if it was out of stock for 40 percent of the period, that’s not a fair signal. Inventory visibility also allows Zenline to prioritize decisions that reduce overstock or avoid out-of-stock risks when delisting or repositioning items.
What if data is incomplete?
Zenline is designed to work in messy retail environments. Our system identifies data gaps, highlights inconsistencies and continues to provide reliable recommendations, without requiring full data cleaning upfront.
Here’s how:
If a product has missing attributes in master data, Zenline uses language models and image recognition to infer likely values
If product variants are not managed properly, Zenline uses similarity matching to find and validate all variants in your data
If competitor mapping is not fully aligned, Zenline runs product similarity models and auto-links comparable items
There’s no need to wait for a full data lake integration. Zenline starts generating recommendations based on what is already accessible and improves continuously as more data becomes available.
What teams gain with Zenline’s data model
Fewer blind spots: Internal and external signals are interpreted together
Faster time to value: No lengthy data integration phase, we’re ready in week one
Better product decisions: Margin, volume and substitution are always in view
Recently published
Thoughts, trends, and practical advice from our team and industry experts.